小E教您学英语
已删除 词源法学英语 GitHub项目
历经02.29-03.08,终于完成了小E的编写,中间修改了无数的坑。当然这款软件包含很多的不足之处,作为python小白的我已经很尽力了。各位看官们,热闹笑话随你们看,只希望能给他人一点微薄的帮助。下面会介绍软件的功能,实现方式等。
软件简介
这是一种旨在使用词源学习法背单词的一种软件[1],视频教程可以参考[2]。
词源学习法的方式是通过一个词源扩展出不同的单词,例如form->conform->conformation。根据宋维钢老师的叙述,这种方式不同于市面上的联想记忆法,通过联想构造一个情形来背单词。这种方式不适用于多个单词,很有可能这种联想方式对于一个单词能够解释明白,另一个单词就矛盾了,而词源学习法是根据词源来学习的,英语中的词源是有依据的,所以不会矛盾。
软件的功能
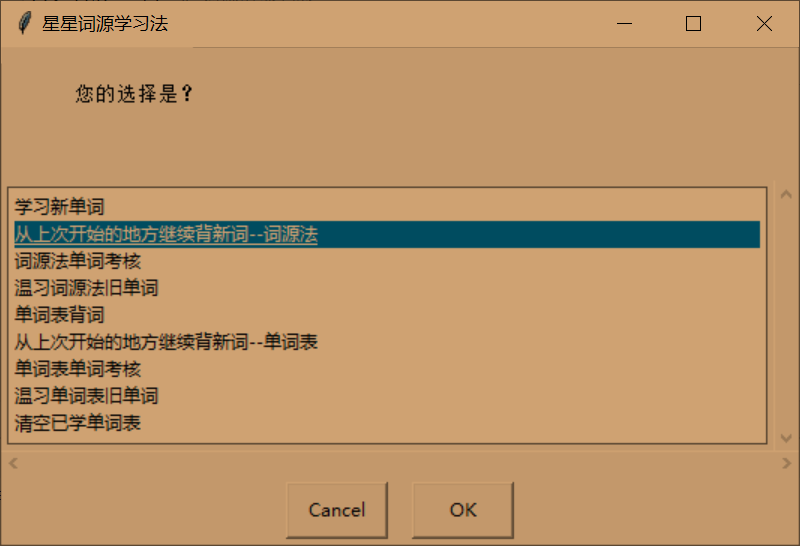
-
学习新单词
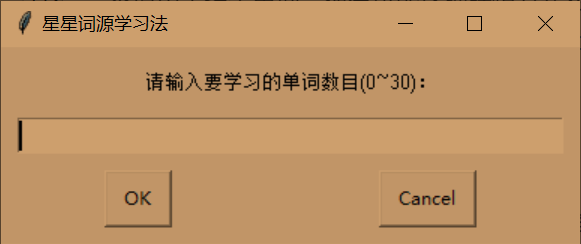
词源法学习新单词,每次学习首先要选择本次要学习的单词数
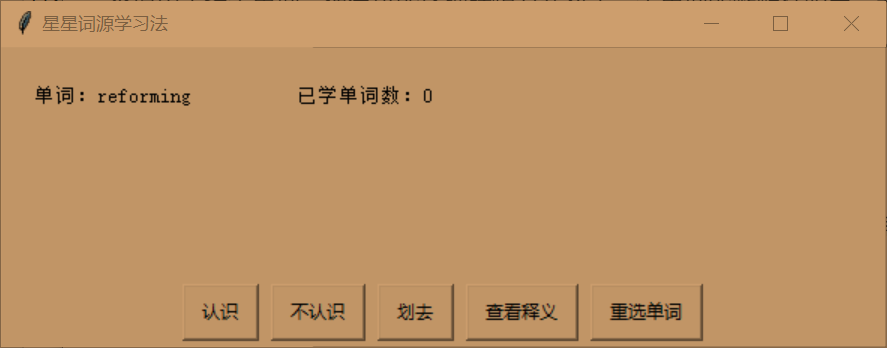
然后会随机选择一个词源,然后学习里面的单词,单词提供认识,不认识,划去,查看释义,重选单词功能。
认识-->得分50分。不认识-->得分零分。划去-->得分200分(不再学习)
查看释义-->查看释义 重选单词-->重新选择单词
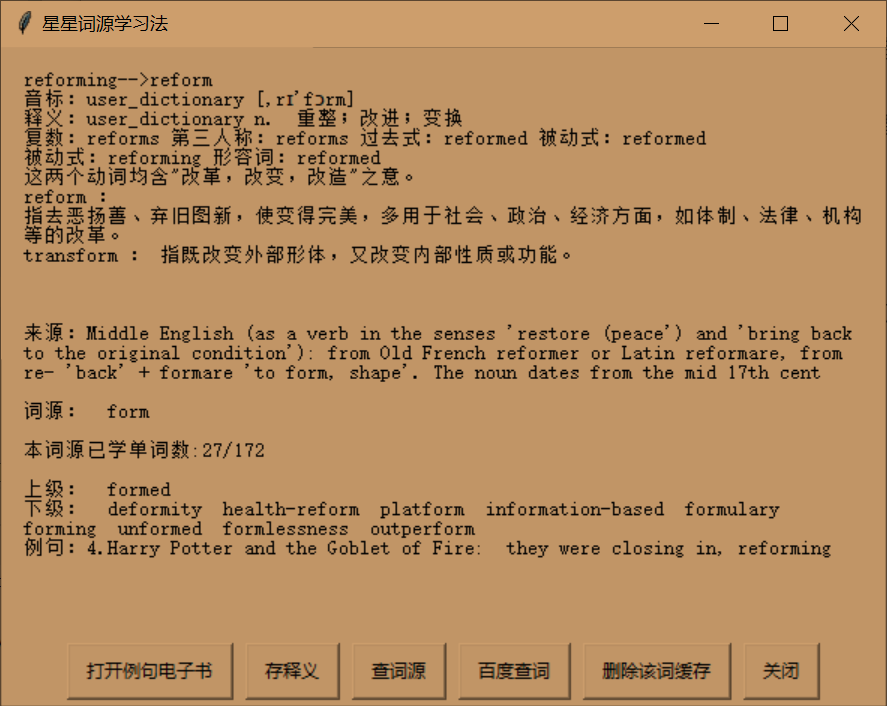
每个单词会包含音标、释义、词形、解析、词源、词源单词表上下级、例句等。其中音标、释义来源于本地词典、金山、bing;词形来源于金山、enchant、textblob;解析来源于金山
词源、上下级来源于词源单词表;例句来源于本地、金山、书籍、字幕。
-
从上次开始的地方继续背新词词源法
软件退出后会记录学习位置,下次进入可以继续从这个单词继续学习。
-
词源法单词考核
拼写-->得分80分
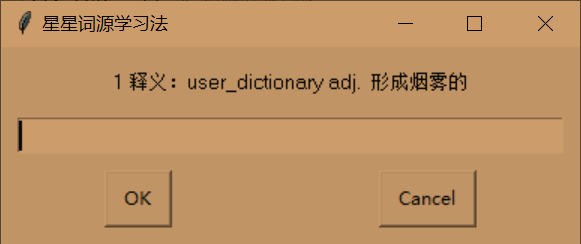
听写-->得分90分
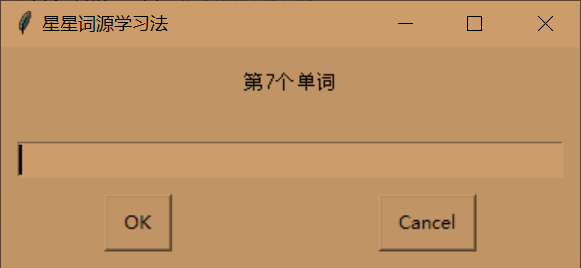
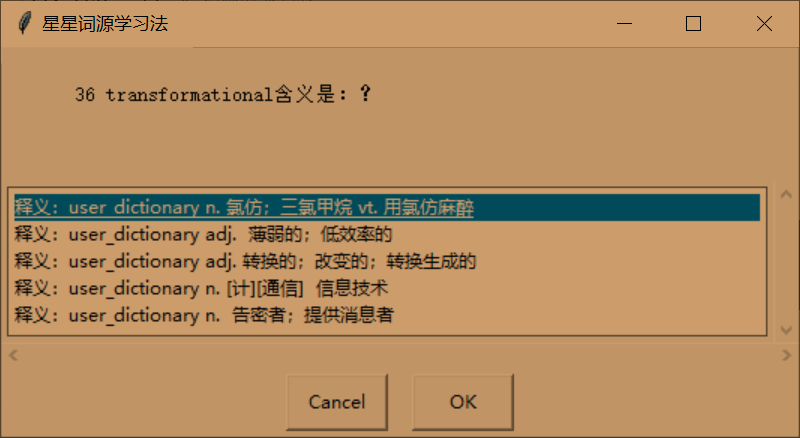
选择-->得分100分
-
温习词源法旧单词
得分100分的单词可以再次学习,复用学习新单词的功能 -
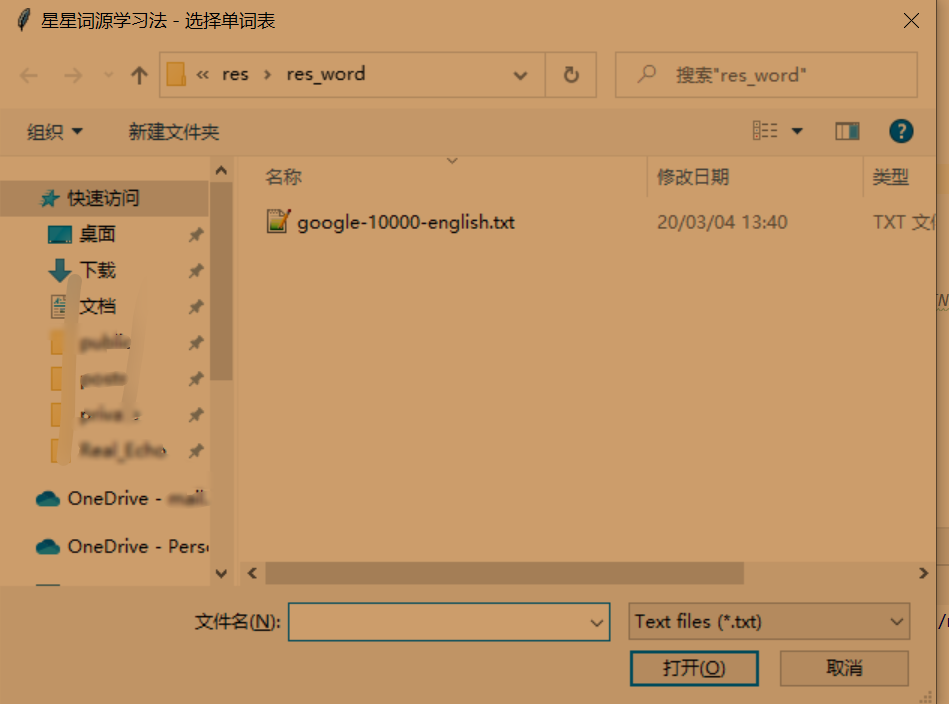
单词表背词
选择单词表
其他除了没有词源上下级之外,功能一样。 -
从上次开始的地方继续背新词-单词表
-
单词表单词考核
-
温习单词表旧单词
-
导出xml
-
导入xml
-
清空已学单词表
清空词源法得分表和单词表得分表,不建议删除。不过误删有备份功能,备份本次删除的数据在./config/copy/当年-当月-当日_当时-当分-当秒/下,恢复数据仅需复制覆盖即可。
软件的输入
词源单词表
路径:./res/res_md
由思维导图软件xmind_zen导出markdown文件作为软件的词源单词表,生成范例可以参考res_xmind目录 [./res/res_xmind]下的文件。
普通单词表
路径:./res/res_word
由用户选择文本文件,读取后作为单词表。文本文件里的单词表格式为“英语单词+空格+其他” 软件仅读取空格前的英语单词。
英语书籍
路径:./res/res_book
大家都推荐学习英语单词时使用英语书籍里的句子作为单词例句。
英语字幕ASS
路径:./res/res_srt 仅支持.ass的文件
大家都推荐学习英语单词时使用英语字幕里的句子作为单词例句。
用户词典
路径:./res/res_dict
英语单词的释义可以通过本地用户词典来获得。词典格式为:英语单词+空格+英语释义+【英语解析】
学过的单词
路径:./res/res_know
用户学过的单词可以写在一个txt里,然后这里的单词就不会再学习了
导入xml
路径:自己给定 有道生成的xml文件 金山词霸的txt可以用有道转成xml然后再导入该软件
会导出单词表在./res/res_word和词典在./res/res_dict内
音效
路径:./Sound_Effect
用在拼写单词或选择单词释义正确与否的时候播放音效。
软件的输出
单词得分表.txt
路径:./res/record
每个学习的单词都有得分,在得分变动后,关闭软件之前,会记录在单词得分表.txt里。
单词意思.txt
路径:./res/record
每个英语单词的释义是可以存下来的。存下来以后可以可以在txt里更加舒服的看单词的意思,因为软件的GUI很简单,所以看着可能不舒服。
格式化书籍
路径:./res/res_formatted_book
格式化后的书籍文件会存在这里
格式化字幕
路径:./res/res_formatted_srt
格式化后的字幕文件会存在这里
读音
路径:./Speech_EN和./Speech_US
每个学过的单词读音会存在这两个文件夹里
导出xml
路径:./export
选择单词表导出xml文件供有道词典和金山词霸单词本使用
导入xml生成的txt
路径:./res/res_word和./res/res_dict
会导出单词表在./res/res_word和词典在./res/res_dict内
配置文件
路径:./config
pkl后缀文件,由pickle来保存一些软件退出后该保存的配置。
- book.pkl用于存放已经处理过的书籍列表。由于书籍文件杂乱不齐,所以在起始时会进行处理,但是处理耗时,如果每次都处理会影响软件打开的时间,所以仅处理新增的文件。
- cloud.pkl用于存放云端下载的文件,包括音标、释义、例句、解析、单词变形等等。
- etmology_status.pkl 保存词源学习法每次退出前的单词位置。
- word_tab_status.pkl 保存单词表学习法每次退出前的单词位置
- word_mean.pkl 每一个存在单词意思.txt里的单词只能有一个,这是为了不重复保存相同的单词,便于保存
- word_score.pkl 词源法单词得分 每一个词源法学过的单词都会存在这个里面
- word_tab_score.pkl 单词表得分 每一个通过单词表学过的单词都会存在这个里面
- srt.pkl 用于存放已经处理过的字幕列表。由于书籍文件杂乱不齐,所以在起始时会进行处理,但是处理耗时,如果每次都处理会影响软件打开的时间,所以仅处理新增的文件。
软件思维导图
小E的思维导图 小E的程序结构思维导图可以清晰的表示出该软件的实现流程。
软件使用的库
内置库:time,sys,os,random
爬虫:urllib
外置库:GUI:easygui
文件存储:pickle
单词大小写、有效性检查:textblob、enchant
执行bat,GUI:pywin32
编码检测:chardet
爬虫:requests
xml文件:lxml
执行js代码:PyExecJs
软件程序的内容
每一部分实现的方法
主函数main.py
# Disable
def blockPrint():
sys.stdout = open(os.devnull, 'w')
# Restore
def enablePrint():
sys.stdout = sys.__stdout__
- 生成词源类对象
利用读取文本文件的方式读取,通过观测词源文件的结构,可以发现词源为1个‘#’,其他的就是词源单词表,每个单词前面有#、-、空格,通过这个,就可以计算词源单词表中每个单词的数目。
def read_markdown(file_name):
"""
:param file_name: Xmin_ZEN生成的markdown文件
:return: word_etymology:词源
word_list:该词源对应的词源列表
level_list:每一个单词在词源列表中代表的级数,
对应markdown内部的级数,表明单词与词源关系的大小
word_num:该词源包含的单词数目
"""
level_list = []
word_list = []
# word_etymology = ' '
# word_num = 0
if os.path.exists(file_name):
f = open(file_name, encoding='utf-8') # 打开词源文件
level_underline = 4 # 下划线的级别
word_etymology = f.readline().strip('# ' + os.linesep) # 第一行为词源
for each in f:
if '# ' in each:
level_list.append(each.count('#'))
word_list.append(each.strip('# ' + os.linesep)) # 去除换行符和空格
elif '- ' in each:
each = each.strip(os.linesep) # 去除换行符
each = each.split('- ') # 以中划线和空格分割
word_list.append(each[1])
# 计算级别,中划线是4级,因为3个#之后才会出现中划线,中划线之后的级别以\t区份
level_list.append(level_underline + each[0].count('\t'))
else:
pass
f.close()
word_num = len(word_list)
assert word_num == len(level_list) python# 如果不相等就会异常 false报异常
else:
return
return word_etymology, word_list, level_list, word_num
词源类etymology.py
可以更好的把词源单词表封装起来,每个词源对象对应一个词源文件。
单词学习类word_learning.py
-
!!!不足:
- 这个类过于复杂,把所有的功能几乎都封装再这个库里了,虽然使得主函数很简单,但是类的思想被破坏了。
- 初始化的东西太多了,这也是这个类复杂导致的
- 重复写的东西太多,有些东西本来可以分成多个部分,然后用上继承的思想,但是过于复杂,儿子继承了可能也很懵吧
-
!!!改进:
- 把各个功能模块拆分,最好封装成不同的类,比如把词源学习法和单词表学习法分开,然后基类是读写单词等等,子类从父类继承
- 主函数适当的扩充些内容,使类的东西稍微简单点,初始化的东西少一点
-
主要函数:learn_word 400多行,分别介绍吧,实际上思想很简单,就是复写了好几遍导致代码比较多
- 开始:功能选择:以下为框架代码:
learning_way = ['学习新单词', '词源法单词考核', '从上次开始的地方继续背新词--词源法', '温习词源法旧单词',
'单词表背词', '单词表单词考核', '从上次开始的地方继续背新词--单词表', '温习单词表旧单词'] # 学习方式 0 1 2 3 4 5 6 7
exit_status = '退出' # 退出学习的标志
clear_status = '清空已学单词表' # 清除选项
export_status = '导出xml'
way_choice = self.__way_form()
if way_choice is None: # 不选就退出
return self.word_num, self.left_word_num
if way_choice == self.export_status: # 导出xml
if way_choice == self.clear_status: # 清空单词表
if way_choice == self.learning_way[0] or way_choice == self.learning_way[2] or way_choice == self.learning_way[3]:
-
不足:我为什么要把learning_way写成列表!!!!后面写各个功能实现的时候,我经常发疯,不知道自己到底在写哪个功能。。
-
这部分可以放在主函数里,这样功能就可以分多个文件来写了。
-
之所以有些功能放在一起,是因为大部分都是一样的,比如learning_way[0,2,3]他们的界面都是一样的,区别在于学习的单词不同,所以在实现他们的时候放在一起了。
-
学习单词数量选择
上面的功能选择也涉及到了GUI,这里选择的是easygui
import easygui as gui
def __start_form(self):
"""
开始选择背单词单词数目
:return:
"""
msg = '请输入要学习的单词数目(0~30):'
word_num = gui.integerbox(msg, self.title) # 这一轮背单词数目
if word_num is not None:
if 30 >= word_num > 0:
return int(word_num) # 只允许最多背30个单词
else:
gui.msgbox("请不要输入小于0大于30的数字!", ok_button="OK") # 提示单词小于30
self.__start_form() # 递归调用
else:
return None # 返回退出标志
- 功能:学习新单词,从上次开始的地方继续背新词--词源法,温习词源法旧单词
-
-
这三个的窗口界面是一样的。词源法是指选择一个词源,然后本次的内容就背诵该词源单词表里的单词(由词源对象提供)
-
新单词不在单词得分表里,从上次开始的地方继续背新词--词源法是指软件需要记住退出后学习的单词列表及在单词列表中的位置。温习词源法旧单词是指单词在单词得分表里是100分。
-
当然,还需要考虑三种情况都需要考虑的内容:单词的位置不能超过列表长度,当位置移动到单词列表末尾就需要重新选择单词列表
-
def __choose_ety_start_pos(self, way_choice, score_high=0, score_low=0):
# 2020.03.04选择从列表中选取一定数量的没背过的单词供这一轮使用,那么后面背单词过程出现错误的可能性就比较小
ety = None
start_pos = None
word = None
random.shuffle(self.etymology_list) # 洗词源
for each_ety in self.etymology_list:
print('正在查找词源 %s' % each_ety.word_etymology)
random.shuffle(each_ety.word_list) # 洗词源里的列表
for each_word_pos in range(len(each_ety.word_list)):
each_word = each_ety.word_list[each_word_pos]
if way_choice == self.learning_way[0] or way_choice == self.learning_way[
2] and each_word not in self.word_score_dict:
ety = each_ety
start_pos = each_word_pos
word = each_word
print('不在单词得分表中 已经找到词源:%s 在词源单词表中的位置:%d 起始单词:%s' % (ety.word_etymology, start_pos, word))
return ety, start_pos, word
elif (way_choice == self.learning_way[1] or way_choice == self.learning_way[3]) \
and each_word in self.word_score_dict \
and score_low <= self.word_score_dict[each_word] <= score_high: # 这里的or一定要加括号!
ety = each_ety
start_pos = each_word_pos
word = each_word
print('在单词得分表中 已经找到词源:%s 在词源单词表中的位置:%d 起始单词:%s 得分:%d'
% (ety.word_etymology, start_pos, word, self.word_score_dict[each_word]))
return ety, start_pos, word
else:
pass
print('未找到 均已经学完')
return ety, start_pos, word
如上所示,选择单词的起始位置,是通过功能方式进行判断的,不同的条件能选出不同的单词,然后后面只需要选择列表中的元素即可。这部分比较考验逻辑能力,需要注意很多,比如筛选条件是不是会重合,矛盾?会不会出现列表越界?如果所有单词都学完了,是不是会无限循环查找?
- 对于单词考核界面,主要包含单词选择,听写,拼写。单词选择是随机从单词表里选择单词,其中包含正确单词,然后翻译,得到界面。听写是播放单词的读音,然后用easygui的enterbox。拼写是显示单词的释义,也是用easygui的enterbox。
功能细分
考虑到泛泛的说会招人烦,所以我准备功能细分来说。这样我也能把细分的功能原理给研究研究。
txt编码检测
在读取用户给出的书籍或者字幕文件时,文件编码凌乱,如果只选择一种编码会造成异常,当然可以通过try except跳过这个文件,但是尽可能多的读取文件才是最好的,因此有了编码检测
def detectCode(self,file_path):
with open(file_path, 'rb') as file:
data = file.read(200000)
dicts = chardet.detect(data)
# print('编码:%s\n' %dicts["encoding"])
return dicts["encoding"]
单词有效性检查
用户给出的单词不一定是正确的,所以需要进行单词有效性检测。
>>> import enchant
>>> d = enchant.Dict("en_US")
>>> d.check("Hello")
True
>>> d.check("Helo")
False
>>> d.suggest("Helo")
['He lo', 'He-lo', 'Hello', 'Helot', 'Help', 'Halo', 'Hell', 'Held', 'Helm', 'Hero', "He'll"]
>>>
单词单复数 动词原形
TextBlob 只是这个功能也很蠢,因为名词也有可数和不可数。。但是这里并不区分。不过用来作为查词容错的工具是不错的,如果要查的单词查不到,那么单数,复数,动词原形以及enchant的suggest列表里的是不是有呢?
>>> sentence = TextBlob('Use 4 spaces per indentation level.')
>>> sentence.words
WordList(['Use', '4', 'spaces', 'per', 'indentation', 'level'])
>>> sentence.words[2].singularize()
'space'
>>> sentence.words[-1].pluralize()
'levels'
request模块
所以我优先会选用金山的翻译,金山的API很好用,例句,词典,单词单复数等等应有尽有。
def get_synword_exchange(string):
print('金山同义词查询 %s' % string)
time.sleep(0.02)
data = ''
# 请求API
url = 'http://www.iciba.com/index.php?a=getWordMean&c=search&word=' + string
try:
req = requests.get(url, timeout=2)
# 处理返回的JSON数据
info = req.json()
if 'baesInfo' in info:
if 'exchange' in info['baesInfo']:
print('exchange')
if 'word_pl' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_pl']) > 0:
data += '复数:' + info['baesInfo']['exchange']['word_pl'][0] + ' '
if 'word_third' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_third']) > 0:
data += '第三人称:' + info['baesInfo']['exchange']['word_third'][0] + ' '
if 'word_past' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_past']) > 0:
data += '过去式:' + info['baesInfo']['exchange']['word_past'][0] + ' '
if 'word_done' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_done']) > 0:
data += '被动式:' + info['baesInfo']['exchange']['word_done'][0] + ' '
if 'word_ing' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_ing']) > 0:
data += '被动式:' + info['baesInfo']['exchange']['word_ing'][0] + ' '
if 'word_adv' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_adv']) > 0:
data += '副词:' + info['baesInfo']['exchange']['word_adv'][0] + ' '
if 'word_verb' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_verb']) > 0:
data += '动词:' + info['baesInfo']['exchange']['word_verb'][0] + ' '
if 'word_noun' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_noun']) > 0:
data += '名词:' + info['baesInfo']['exchange']['word_noun'][0] + ' '
if 'word_adj' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_adj']) > 0:
data += '形容词:' + info['baesInfo']['exchange']['word_adj'][0] + ' '
if 'word_prep' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_prep']) > 0:
data += '介词:' + info['baesInfo']['exchange']['word_prep'][0] + ' '
if 'word_er' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_er']) > 0:
data += '比较级:' + info['baesInfo']['exchange']['word_er'][0] + ' '
if 'word_est' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_est']) > 0:
data += '最高级:' + info['baesInfo']['exchange']['word_est'][0] + ' '
if 'word_conn' in info['baesInfo']['exchange'] and len(info['baesInfo']['exchange']['word_conn']) > 0:
data += '最高级:' + info['baesInfo']['exchange']['word_conn'][0] + ' '
if len(data) > 1:
data += '\n'
if 'synonym' in info:
print('synonym')
for each in info['synonym']:
if 'part_name' in each:
data += each['part_name']
if 'means' in each:
for each_mean in each['means']:
data += each_mean['word_mean'] + ':' + str(each_mean['cis']) + '\n'
if 'sameAnalysis' in info:
print('sameAnalysis')
for each in info['sameAnalysis']:
if 'part_name' in each:
data += each['part_name']+'\n'
if 'means' in each:
for each_mean in each['means']:
data += each_mean + '\n'
if len(data) > 1:
data += '\n'
if 'exchanges' in info:
for each in info['exchanges']:
if each not in info['exchanges']:
data += each + ' '
if len(data) > 1:
data += '\n'
except Exception as ex:
print('出现异常 %s' % ex)
data = None
# print('数据长度:%d' % len(data))
if data and len(data) <= 1:
print('数据长度:%d' % len(data))
print('舍弃为1的data')
data = None
return data
当然上述功能,TextBlob也有提供,当然依旧不好用
>>> from textblob import Word
>>> from textblob.wordnet import VERB
>>> word = Word("octopus")
>>> word.synsets
[Synset('octopus.n.01'), Synset('octopus.n.02')]
>>> Word("hack").get_synsets(pos=VERB)
[Synset('chop.v.05'), Synset('hack.v.02'), Synset('hack.v.03'), Synset('hack.v.04'), Synset('hack.v.05'), Synset('hack.v.06'), Synset('hack.v.07'), Synset('hack.v.08')]
request模块设置超时主要是用来设置超时时间,防止程序卡在request过久
API存在失效的情况,我尝试过很多API,发现很多都失效了,比如百度的,bing的等等
url.open 这个应该是爬虫工具了,我找到一个bing的爬虫,可以使用,就是速度很慢
字幕
推荐下载字幕网站
由于下载的字幕是ASS文件所以我使用asstosrt GitHub网址,支持import。
import asstosrt
ass_file = open('example.ass')
srt_str = asstosrt.convert(ass_file)
然后使用库srt
>>> # list() is needed as srt.parse creates a generator
>>> subs = list(srt.parse('''\
... 1
... 00:00:33,843 --> 00:00:38,097
... 地球上只有3%的水是淡水
...
... 2
... 00:00:40,641 --> 00:00:44,687
... 可是这些珍贵的淡水中却充满了惊奇
...
... 3
... 00:00:57,908 --> 00:01:03,414
... 所有陆地生命归根结底都依赖於淡水
...
... '''))
>>> subs
[Subtitle(index=1, start=datetime.timedelta(0, 33, 843000), end=datetime.timedelta(0, 38, 97000), content='地球上只有3%的水是淡水', proprietary=''),
Subtitle(index=2, start=datetime.timedelta(0, 40, 641000), end=datetime.timedelta(0, 44, 687000), content='可是这些珍贵的淡水中却充满了惊奇', proprietary=''),
Subtitle(index=3, start=datetime.timedelta(0, 57, 908000), end=datetime.timedelta(0, 63, 414000), content='所有陆地生命归根结底都依赖於淡水', proprietary='')]
>>> print(srt.compose(subs))
1
00:00:33,843 --> 00:00:38,097
地球上只有3%的水是淡水
2
00:00:40,641 --> 00:00:44,687
可是这些珍贵的淡水中却充满了惊奇
3
00:00:57,908 --> 00:01:03,414
所有陆地生命归根结底都依赖於淡水
文件夹操作
对于文件夹下的文件,以及文件夹下的子文件夹等等一系列问题,我只涉及到了文件夹下的文件和文件夹下的子文件夹。
- 创建文件夹
- 文件后缀名
- 遍历多层文件夹
- 路径的提取,os.path.split os.path.splittext等等
- 绝对路径 os.path.realpath
- 列举文件夹和文件夹下的文件 os.listdir 举个例子,一看便知
def __read(self):
# 遍历文件夹
# 遍历根目录
formatted_flag = False
for dir in os.listdir(self.user_srt_dir):
for file in os.listdir(self.user_srt_dir + dir):
if file not in self.formatted_srt:
formatted_flag = True
if formatted_flag:
win32api.ShellExecute(win32con.NULL, 'open', self.sound_effect_wait, '', '', win32con.SW_HIDE)
for dir in os.listdir(self.user_srt_dir):
format_srt_dir = os.path.join(self.user_formatted_srt_dir, dir)
if not os.path.exists(format_srt_dir): # 不存在格式化的目录就创建一个
os.makedirs(format_srt_dir)
for file in os.listdir(self.user_srt_dir + dir):
if file not in self.formatted_srt:
self.formatted_srt.append(file)
file_name = os.path.join(self.user_srt_dir, dir, file)
print(file_name)
# subs = pysrt.open(file_name, encoding='iso-8859-1')
# print(len(subs))
if file_name.endswith(".ass"):
# format_file = os.path.splitext(file)[0] + '.txt'
format_file = file+'.txt' # 这样可以获得原始文件的后缀名
format_file_name = os.path.join(format_srt_dir, format_file)
print(format_file_name)
ass_file = open(file_name, encoding=self.detectCode(file_name))
srt_str = asstosrt.convert(ass_file)
subtitle_generator = srt.parse(srt_str)
subtitles = list(subtitle_generator)
# print(len(subtitles))
# print(subtitles[1].content)
with open(format_file_name, 'w', encoding='utf-8') as f:
for each in subtitles:
f.write(each.content.replace('\n',' ')+'\n')
return formatted_flag
缓存
一个单词查完音标、释义、例句、解析等等总要耗费一点时间,为了快速的再次读取,需要使用pickle来存放已经查完的单词。
def __read_pkl(self):
with open(self.srt_status_pkl, 'rb') as pickle_file:
self.formatted_srt = pik.load(pickle_file) # 读取配置文件
def __save_pkl(self):
srt_status_dir = os.path.split(self.srt_status_pkl)[0]
if not os.path.exists(srt_status_dir):
os.makedirs(srt_status_dir)
with open(self.srt_status_pkl, 'wb') as pickle_file:
pik.dump(self.formatted_srt, pickle_file)
WIN32.API
弹窗
# 按钮示例
import win32api
import win32con
win32api.MessageBox(None,"Hello,pywin32!","pywin32",win32con.MB_OK)
模拟按键,我利用这个实现了记事本打开,然后查找某个单词
def text_find(txt_path,str):
"""
:param txt_path: txt文件路径
:param str: 查找的字符串
:return:None
"""
txt_path = os.path.realpath(txt_path)
# win32api.ShellExecute(0, 'open', txt_exe,txt_path , '', 1) # 打开txt
win32api.ShellExecute(0, 'open', txt_path, '', '',1) # 打开txt
time.sleep(0.8) # 打开记事本需要时间!!! 不然后面找不到窗口!!
_,txt_name = os.path.split(txt_path)
windows_title = get_windows_title(txt_name)
print('要打开的窗口标题 %s\n' %windows_title)
if windows_title:
show(windows_title)
time.sleep(0.02)
# 按下组合键 ctrl + f
press_key('ctrl', 'f')
# 切换中英文
press_key('shift')
time.sleep(0.02) # 英文切换时间
str=str[0: min(15,len(str))] # 只搜索前10个字符
try:
key_input_str(str)
except Exception as ex:
print('某些字符不知道怎么打印 错误类型:%s' %ex)
time.sleep(0.02) # 搜索需要时间
# 按下enter
press_key('enter')
else:
print('未找到该文件窗口')
win32api还可以打开音乐等等
win32api.ShellExecute(win32con.NULL, 'open', filename, '', '', win32con.SW_HIDE)
我这里的读英语单词就是使用这个办法,pygame播放音乐太占用时间了
lxml库操作xml文件
xml生成
def word_xml(self, root, word, file):
"""
:param root: 父节点
:param word: 单词
:param file: 单词来自的文件
:return:
"""
# 创建一个子节点item,一定要指定父节点
child1 = etree.SubElement(root, 'item')
child1_child1 = etree.SubElement(child1, 'word')
child1_child1.text = word
child1_child2 = etree.SubElement(child1, 'trans')
time.sleep(0.2)
child1_child2.text = self.__intelligent_mean(word)
# child1_child3 = etree.SubElement(child1,'phonetic')
# time.sleep(0.2)
# child1_child3.text = self.__intelligent_yingbiao(word)
child1_child4 = etree.SubElement(child1, 'tags')
child1_child4.text = os.path.splitext(os.path.split(file)[1])[0]
child1_child5 = etree.SubElement(child1, 'progress')
child1_child5.text = '1'
xml解析
tree = etree.parse(file) # 获取树结构
root = tree.getroot() # 获取根节点
word_tab_dir = os.path.split(self.word_tab_default_path)[0]
dict_dir = self.user_dict_dir
word = ''
yingbiao = ''
mean = ''
for elements in root:
for element in elements: # 获取第三层标签
# print(element.tag,':',element.text) #.tag获取节点(标签)名称,.text获取两个标签中间夹着的内容
# if element.tag == 'tags':
# tags=element.text
if element.tag == 'word':
word = element.text
if element.tag == 'phonetic':
yingbiao = element.text
if element.tag == 'trans':
mean = element.text
if element.tag == 'tags':
filename = element.text + time.strftime(" %Y-%m-%d-%H-%M", time.localtime()) + '.txt'
基本内容[3]
字符串操作
例如split,replace
变量
列表、元组、类、魔法方法
函数
函数作为参数来使用
这一点我感觉是我最引以为傲的使用了,我想在各种窗口下面都使用发音函数,那么我在调用各种窗口的时候,调用发音函数,然后把窗口函数以参数方式传入,这样不同模块都可以共用。
def __speak_sound(self, word, speak_types, func, *argc):
# pygame.mixer.init()
filename = self.sp.speak_file(word, speak_types[0])
# audio = MP3(filename)
print("播放音乐1")
# pygame.mixer.music.load(filename)
# pygame.mixer.music.play()
win32api.ShellExecute(win32con.NULL, 'open', filename, '', '', win32con.SW_HIDE)
# 不能做到播放两个音乐
if len(speak_types) > 1:
filename = self.sp.speak_file(word, speak_types[1])
if len(argc) >= 4:
res = func(argc[0], argc[1], argc[2], argc[3], filename)
elif len(argc) == 3:
res = func(argc[0], argc[1], argc[2], filename)
elif len(argc) == 2:
res = func(argc[0], argc[1], filename)
elif len(argc) == 1: # 暂时只使用这个了 用于释义窗口 mean form
res = func(argc[0], filename)
else:
res = func(self, filename)
else:
# 调用form会使程序暂停,不能继续向前走,所以不能重复播放两次,但是如果提前播放音乐看不见窗口
if len(argc) >= 4:
res = func(argc[0], argc[1], argc[2], argc[3])
elif len(argc) == 3:
res = func(argc[0], argc[1], argc[2])
elif len(argc) == 2:
res = func(argc[0], argc[1])
elif len(argc) == 1:
res = func(argc[0])
else:
res = func(self)
# pygame.time.delay(int(audio.info.length)) # 等待单词时间让mp3播放结束
# pygame.mixer.music.stop()
return res
调用:
result = self.__speak_sound(self.word, ['us', 'en'], self.__mean_form, self.word)
正则表达式
使用库re
#过滤@和数字
yingbiao = '[' + re.sub(r'[ˈ0-9@]', "", yingbiao) + ']'
日常使用
第一次想法就是打包成exe,尝试过pyinstaller并没有成功,可能是我错过了很多关键的东西。
翻翻知乎的回答,偶然间看见了嵌入式python,既然这样,那么我就直接使用anaconda下我所使用环境的exe,直接写一个bat,就可以打开了,然后再加个图标,挺省事的,也不用打开编辑器了。
C:\yingyong\anaconda3\envs\Little_E_lib\python.exe C:\Users\Administrator\PycharmProjects\Little_E\main.py·
在编写过程中使用了各个博主的代码加以整合,最终形成了这个软件,感谢各位造轮子的人!!感谢您的观看!!
参考文献:
本文链接:https://WinterStarHu.github.io/post/xiao-e-jiao-nin-xue-ying-yu/
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!